Landscape Generation using Deep Convolutional Generative Adversarial Networks
Minh Hoang & Kenneth Ma
Abstract
In this project, we explore various image generation techniques using Generative Adversarial Networks (GANs) to generate fake images of landscapes. We generate images with 3 different GANs and compared the results. We begin by training an existing Deep Convolution GAN architecture on a Landscape image dataset from Kaggle, downsampling the dataset to 64x64 images and adapting the network to reduce overall training time. Then, we extend this DCGAN network to handle 128x128 and 256x256 images. Since training 256x256 images would take an inordinate amount of time, we compare our results to 256x256 images generated by a StyleGANv3 that was pre-trained on a different landscape dataset instead. For an in-depth overview of our procedure and results, see the summary video here.
Introduction and Problem Statement
Landscapes can be beautiful and inspiring—especially for those fond of hiking and sightseeing. We want to see whether deep learning models trained on landscape images can generate novel landscapes that are as realistic as nature. We began by considering a few types of deep learning models including diffusion models and variational autoencoders. After learning about Generative Adversarial Networks in class, we became interested in the idea of training two models against each other, and decided to make GANs the focus for this project.
We will reimplement Radford et al.’s [1] architecture of DCGAN. We will implement DCGAN to train on a new dataset of landscapes of different sizes and see how well each model performs. Although there have been many more new models developed to solve this problem with higher quality results, we would still choose to re-implement the models of this paper due to their simplicity, robustness, and efficiency in generating images in a fairly short amount of time, and also because this is one of the very well-known GAN models developed to solve this problem. Our code, plots and outputs can be found here.
Related Works
Unsupervised Representation Learning has attracted great interest over recent years. Researchers have tried using many of these kinds of models to generate new images. In addition to GANs, there are also Variational Autoencoders (VAEs) and Stable Diffusion Models. Razavi et al. [2] explored the use of Vector Quantized VAEs to generate diverse images on a larger scale that can be competitively better than GANs on multifaceted datasets like ImageNet. Gorijala and Dukkipati [3] proposed Variational InfoGAN, an extension and combination of VAE and GAN, to generate and modify new images by fixing the latent representation of the image. One of the most well-known architectures for image generation, StyleGAN by Kerras et al [4], applied the use of style transfer literature so the model can automatically learn and unsupervisedly separate high-level attributes in a very efficient manner.
Methodology
We use a Kaggle dataset called “Landscape Pictures” for our project. This dataset consists of 4,319 images of landscapes without any metadata. Since the image sizes are inconsistent, we need to crop and resize the images into specific dimensions. We preprocess the dataset into 3 different dimensions: 64 x 64, 128 x 128 and 256 x 256 pixels.
.jpg)
.jpg)
We reimplement the DCGAN architecture in PyTorch for our initial approach. DCGAN, or Deep Convolutional GAN, consists of 4 transposed convolutional layers. In contrast to traditional CNNs, DCGAN replaces pooling layers with strided convolutions in the discriminator and fractional-strided convolutions in the generator. DCGAN also uses batch normalization layers in both the generator and the discriminator, excludes connected hidden layers, and uses Tanh and Leaky ReLU activation functions. The generator takes in a 100x1 noise vector, and the discriminator takes an vector of 3 x 64 x 64 RGB images as input. The final output of the network is a 3 x 64 x 64 RGB image.
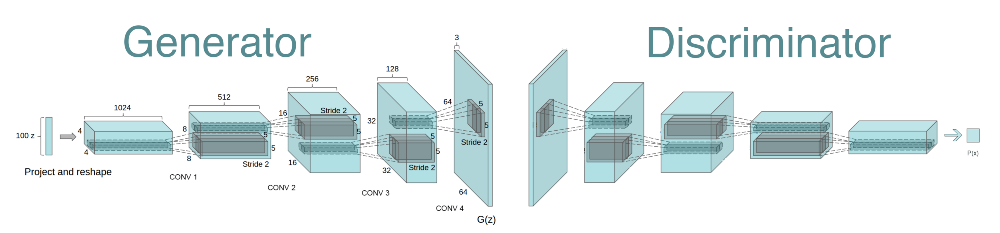 Architecture of DCGAN
Architecture of DCGAN
Experiments
Our first DCGAN network takes in 64 x 64 images. We extend this model to be able to train on larger images. We build 2 deeper DCGAN models, DCGAN128 and DCGAN256 to take 128 x 128 and 256 x 256 input sizes. For each doubling of image height and width, we add 1 additional transposed convolutional layer with double the filter size, along with batch normalization and activation layers, to the generator and discriminator. We also have to adjust the noise input sizes and filter sizes to accommodate the new image sizes. Since DCGAN128 and DCGAN256’s architectures are much deeper and consist of many more parameters, we expect the training time to also be much longer.
DCGAN was originally trained on CelebA with a batch size of 128 and learning rate of 0.0002, and we will use the same hyperparameters to train our models. We will also use binary cross-entropy loss and Adam optimizer for both the generator and discriminator, similar to the original implementation. Being able to train GANs to generate new images requires a very large number of epochs, but due to our limited time and computational resources, we will train for a smaller number of epochs relative to the original paper. Specifically, we will train DCGAN for 2000 epochs, DCGAN128 for 1000 epochs, and DCGAN256 for 500 epochs.
In addition to training our 3 DCGAN models, we also feed part of the LHQ256 dataset, originally consisting of 90000 256 x 256 landscape images, into a pre-trained StyleGANv3 network to compare the outputs.
Model Evaluation
Since our experiments do not control for variables (we use different model architectures trained on different datasets for different amounts of time) the goal of our project is less about comparing specific training methods and more about conducting an exploration of various GAN networks to generate the “best-looking” landscape images possible. We acknowledge that “best-looking” is quite subjective. Therefore, we’ll showcase our results by making side-by-side comparisons between images generated by different networks and describe any patterns observed.
Results
Model Performance
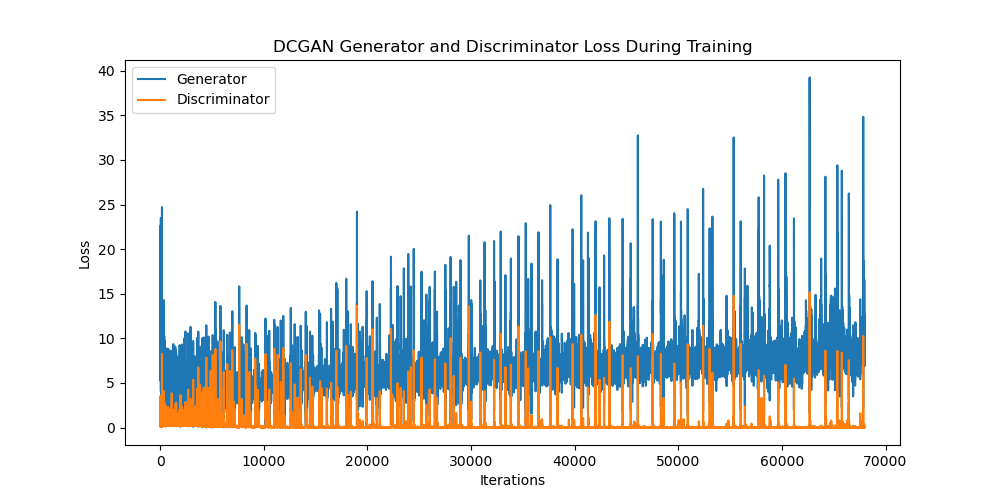
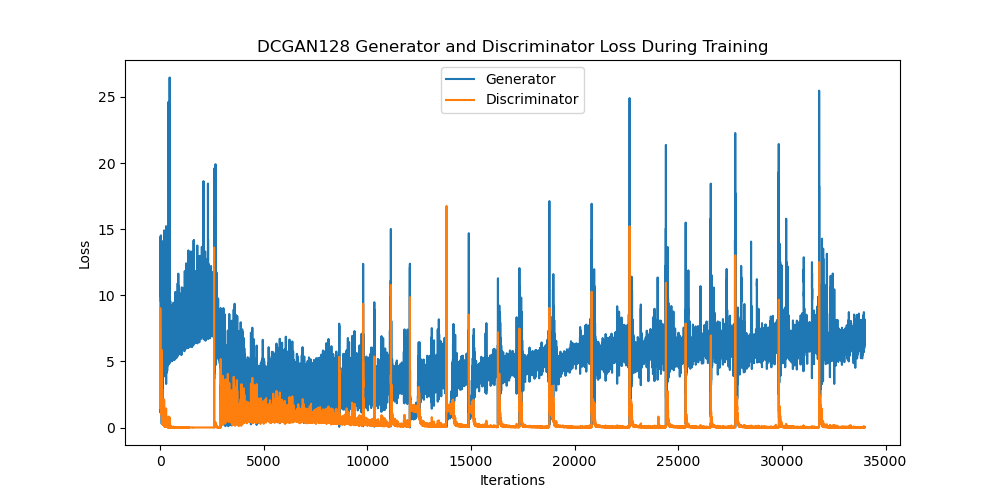
For the original DCGAN model, training 2000 epochs takes about 2.5 hours on CUDA with a RTX 3060 GPU (average of 3 - 5 seconds per epoch) and about 8 hours on a CPU. For DCGAN128, training 1000 epochs takes about 8 hours on GPU (average of 27 - 30 seconds per epoch). For DCGAN256, we were unable to train our model due to CUDA running out of memory when feeding input through the network. Therefore, we could not generate any plots or results for our DCGAN256 experiment.
For the other 2 models, with the same learning rate and batch size, we can look at the plots and see that overall, the loss of DCGAN128 is smaller and fluctuates less than that of DCGAN, even though DCGAN128 was trained for half as many epochs. The generator’s loss in both models reaches approximately 25 in the first 35000 iterations, but way less often in DCGAN128. Similarly, the discriminator’s loss in both models reaches maximum of 15, but less often for DCGAN128.
Results
Comparisons

 Comparisons between real and fake images generated by DCGAN models
Comparisons between real and fake images generated by DCGAN models
Overall, the generated results from the DCGAN128 are more realistic. Several of them look like beach landscapes, with blue-gray skies, beige sandbars and darker brown mountain ranges in-between. It seems the model has gotten quite good at generating these kinds of landscapes, where the different features organized into horizontal layers. If these images were inputs for an image segmentation task, they would likely be fairly easy to predict. We can also observe another archetype of generated images that are covered in green splotches. In particular, the image in row 4 column 2 (DCGAN128 Fake Images) looks like a bit like a waterfall. It’s possible that the green splotches are supposed to be trees and shrubbery of some sort, which would make sense next to a waterfall. However, such landscapes are segmented into many more regions than the aforementioned beach landscapes. These would be harder inputs for an image segmentation task, and this could also be why the model has a harder time generating realistic versions. Finally, we also see a few images with orange skies. It’s possible that this pattern was learned from sunset samples like row 2 column 6 (DCGAN128 Real Images).
Even though we trained our first DCGAN for 2000 epochs, the generated results are still quite blurry when compared to the results of the DCGAN128. This also corresponds with the loss plot for DCGAN having greater flucutations compared to that of DCGAN128. Given the detailed nature of landscape images, it may be harder to learn the important features of the whole landscape when the dimension of the images are too small. Compared to CelebA and MNIST, the datasets that DCGAN was originally trained on, landscape images may also generally have greater variance since A) landscapes can look wildly different from one another, and B) the main features (faces and digits) are not pre-centered. Therefore, by having an additional layer to learn features from larger images, DCGAN128 was able to capture more of this variance and generate more realistic outputs in fewer epochs.
Animation: Fake Image Generation
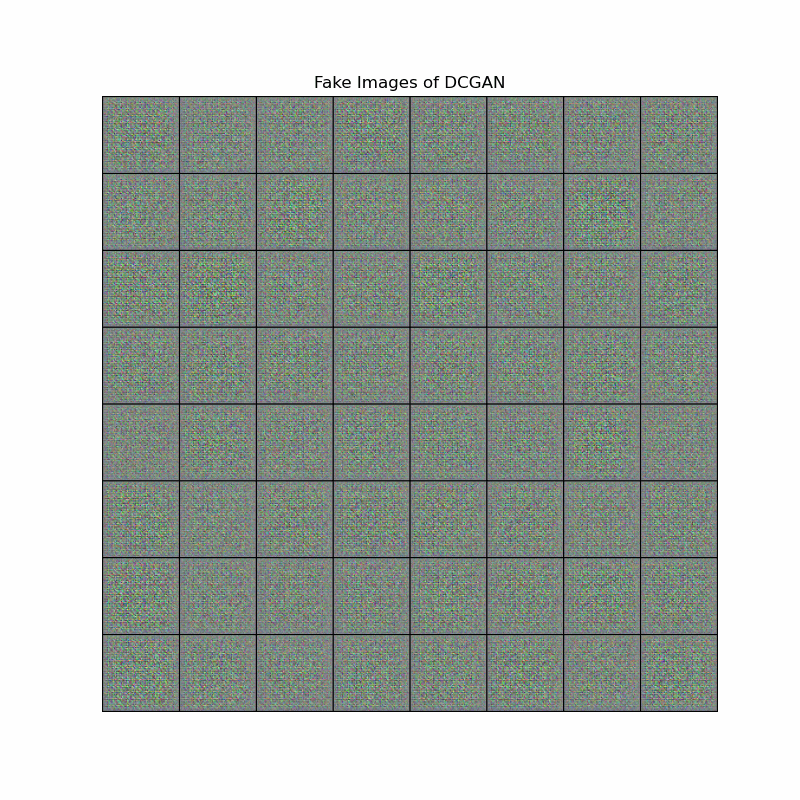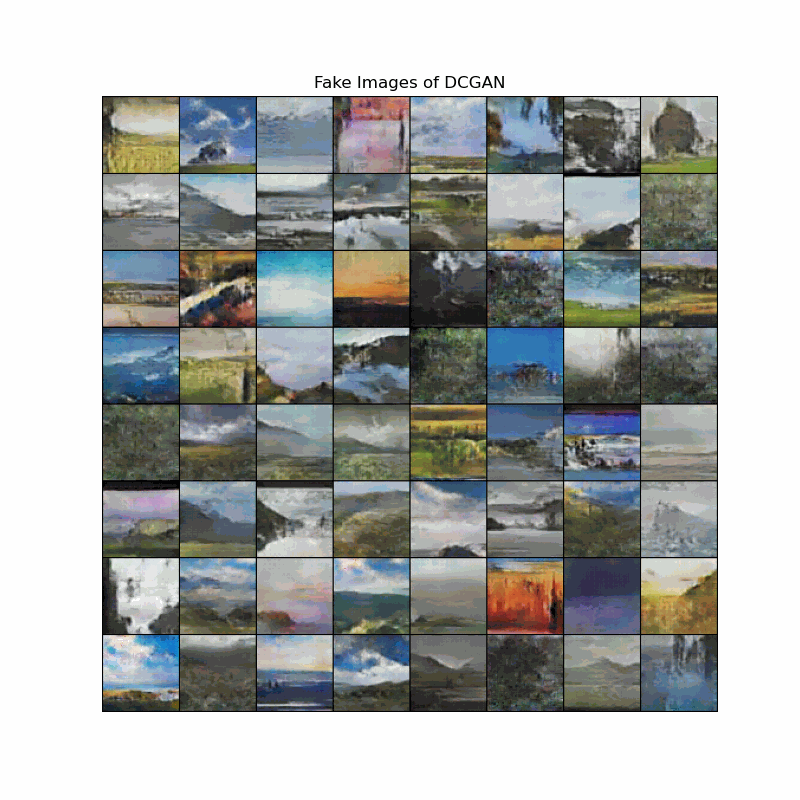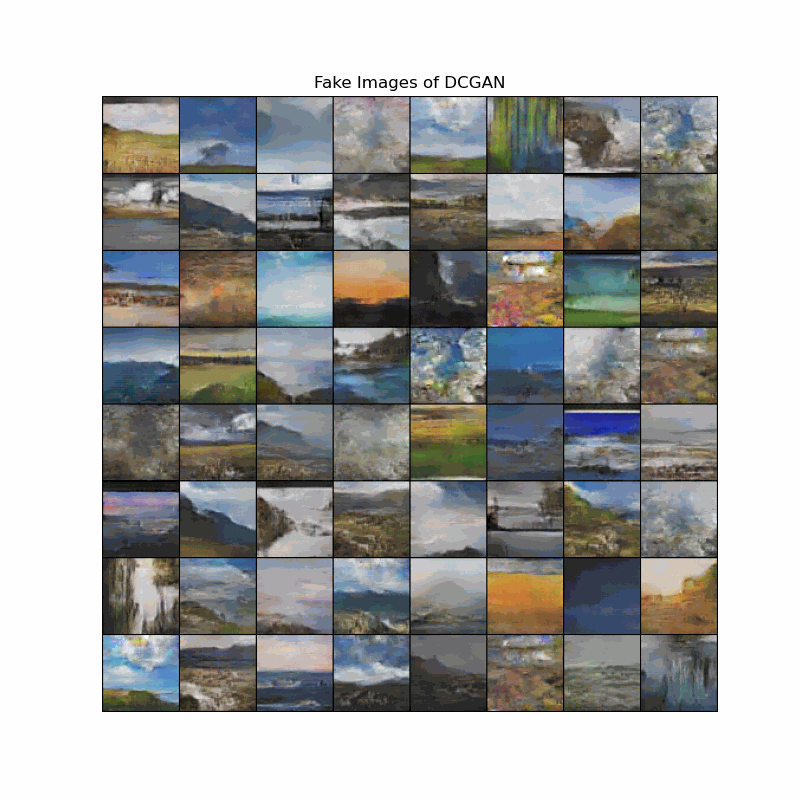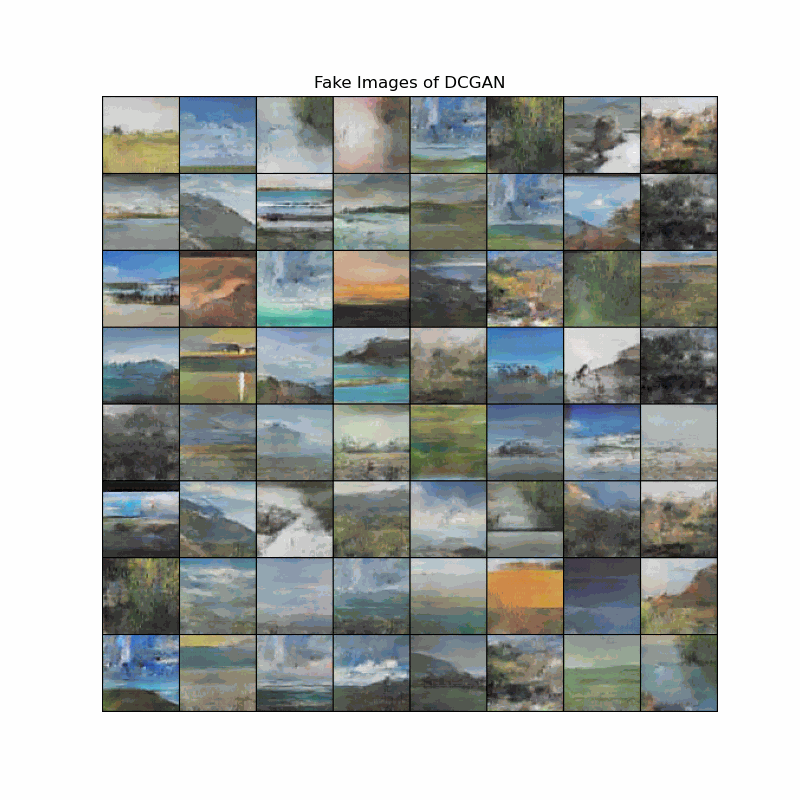
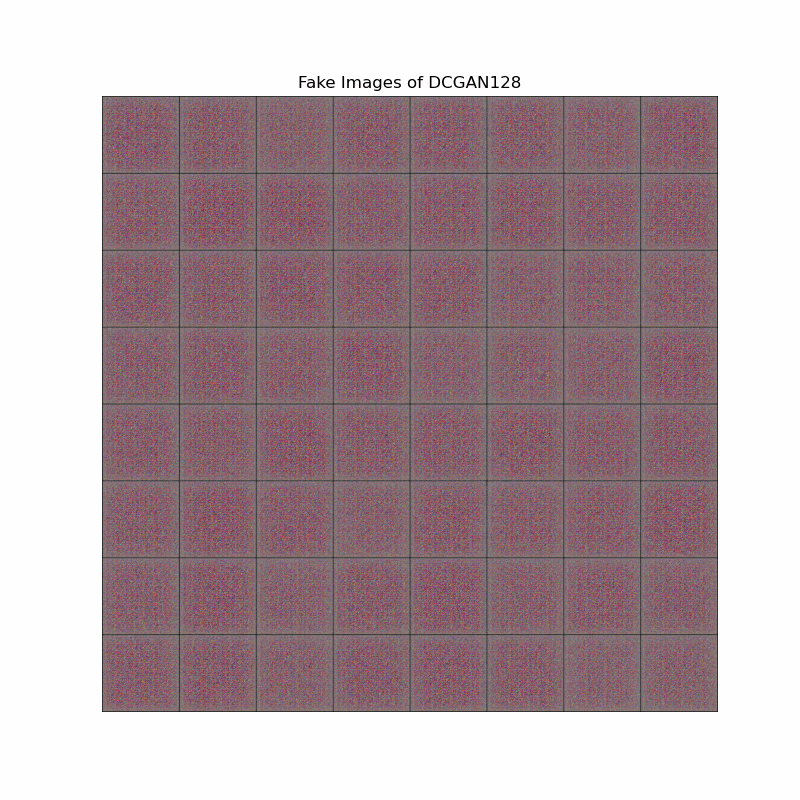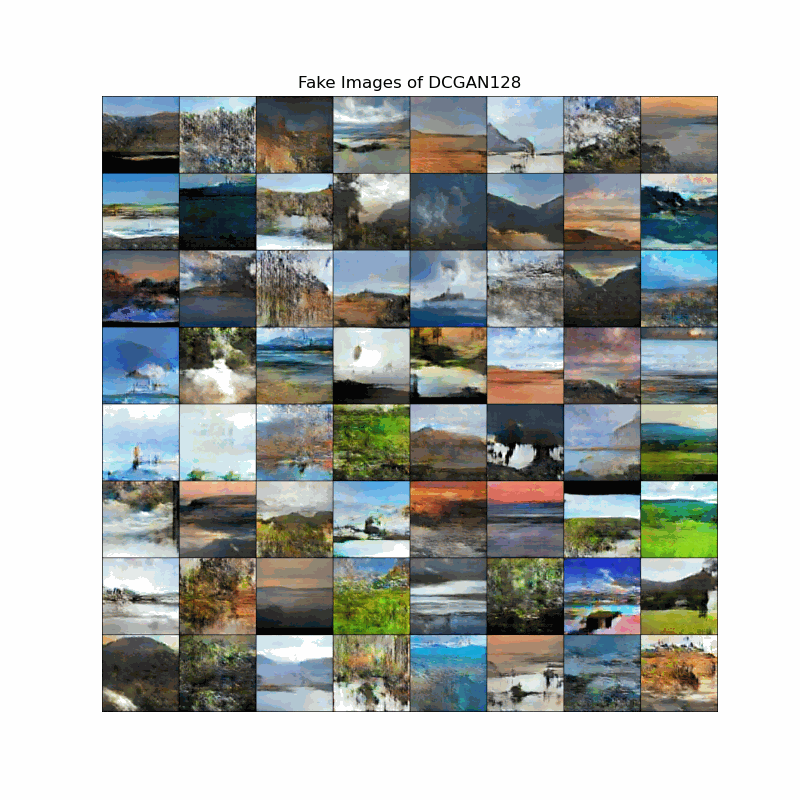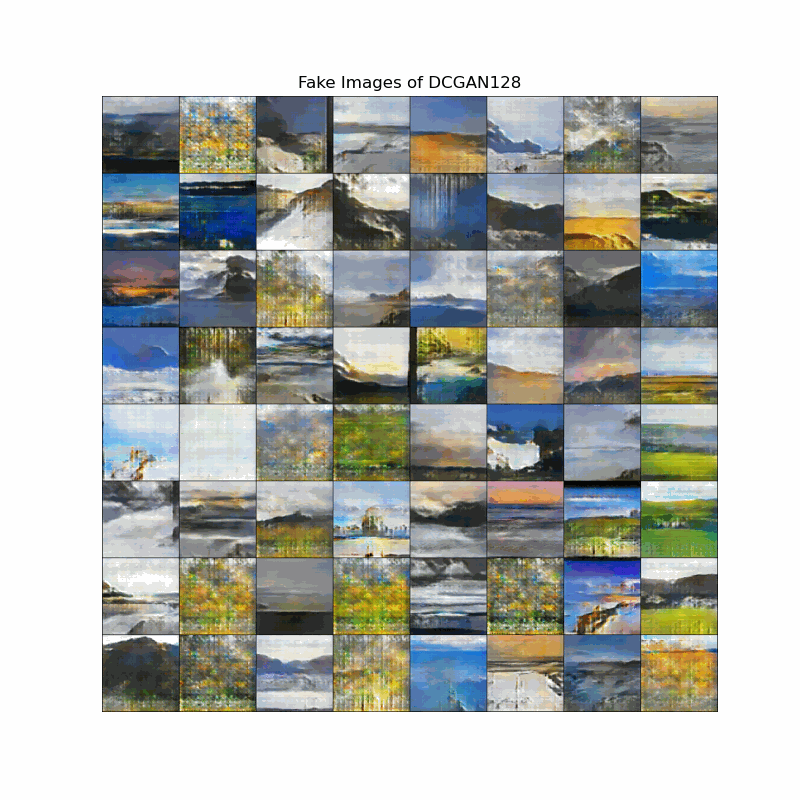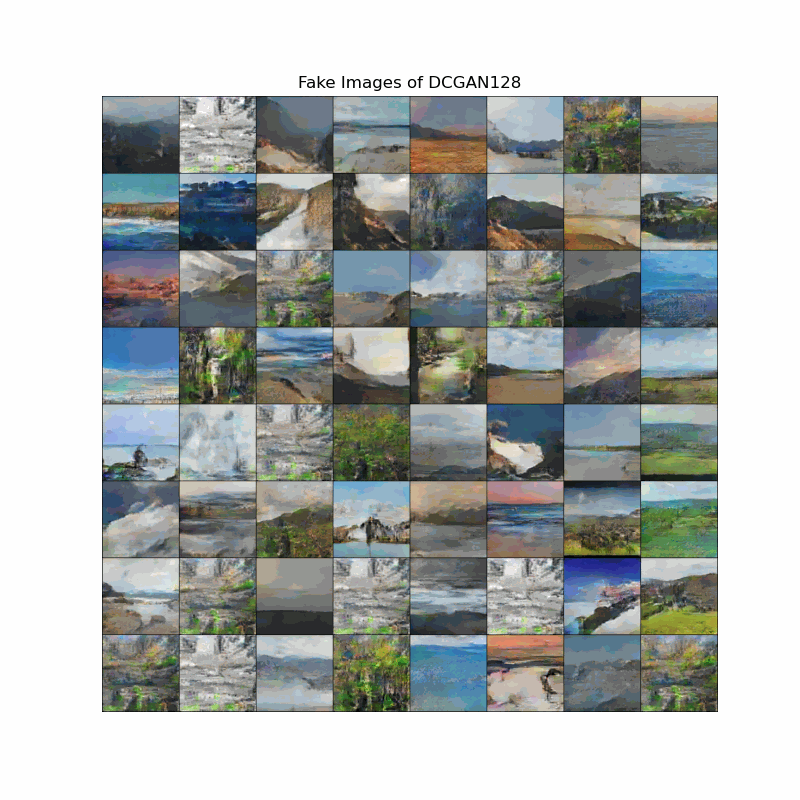 Fake image evolution of DCGAN models
Fake image evolution of DCGAN models
The animation shows how the landscapes start to take shape as the models discover important edges. We can observe that DCGAN learns landscape features slower the DCGAN128, although the end results of both models are still blurry to some degree.

The animation clearly shows how superior StyleGANv3 is compared to DCGAN in generating realistic outputs. This is expected, since StyleGANv3 was pre-trained on multiple GPUs for several days (average of 72.7s / 1000 images) on a much larger dataset (LHQ dataset).
Conclusion and Future Works
During this project, we reimplemented and extended the architecture of DCGAN to work with multiple image sizes. We observed that in order to train larger images, a deeper DCGAN network is required, and that the deeper the network is, the better it is a generating realistic outputs.
We also see that the DCGAN-generated outputs are still not very realistic compared to the outputs from the pre-trained StyleGANv3. Our time constraints meant we were only able to train our DCGANs for a small number of epochs. We were also unable to train our model on 256 x 256 images due to computational limitations. Additionally, we note that our dataset is fairly small, and may not be sufficient for generating images that can transition smoothly between different landscapes like the output of StyleGANv3 (which was trained on a much larger dataset - LHQ). Therefore, if we were to continue our project, with more GPUs and time, we would train our DCGAN models on the full LHQ dataset for a fairly large number of epochs (50000 to 80000) to see how realistic our output can become.
References
[1] Alec Radford, Luke Metz, Soumith Chintala. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. ICLR (Poster) 2016.
[2] Ali Razavi, Aäron van den Oord, and Oriol Vinyals. 2019. Generating diverse high-fidelity images with VQ-VAE-2. Proceedings of the 33rd International Conference on Neural Information Processing Systems. Curran Associates Inc., Red Hook, NY, USA, Article 1331, 14866–14876.
[3] Mahesh Gorijala and Ambedkar Dukkipati. “Image Generation and Editing with Variational Info Generative AdversarialNetworks.” ArXiv abs/1701.04568 (2017).
[4] T. Karras, S. Laine and T. Aila, “A Style-Based Generator Architecture for Generative Adversarial Networks” in IEEE Transactions on Pattern Analysis & Machine Intelligence, vol. 43, no. 12, pp. 4217-4228, 2021. doi: 10.1109/TPAMI.2020.2970919.